
Reputation is now infrastructure

Reputation is now infrastructure
Jahrzehntelang wurde Reputation als Kommunikationsproblem behandelt.
When a crisis breaks, you’re no longer just managing reporters and social media. Within minutes, AI assistants assemble the first draft of your story from whatever they can parse: your website, past coverage, and open-knowledge sources. If those surfaces are thin, fragmented, or outdated, machines will fill the gaps fast. That first hour now shapes days of headlines and weeks of perception [10].
What today’s machines actually read
Modern search and AI experiences lean on two pillars:
- Structured facts on your site (schema.org/JSON-LD) to disambiguate your entity (organization, people, products). Google recommends JSON-LD and warns against blocking structured pages [1][2].
- Knowledge-graph sources (for example, Wikipedia/Wikidata) and other web signals that feed knowledge panels and instant answers, which are compiled from various sources across the web [3][4][5].
Translation: if your owned facts aren’t machine-readable — and your open-web facts aren’t aligned — AI will summarize an outdated or biased version of you.
Why hallucinations raise the stakes
Large language models can produce fluent but incorrect claims when sources are sparse or conflicting. Grounding responses in reliable, structured data reduces this risk — but only if that data exists and is consistent [10].
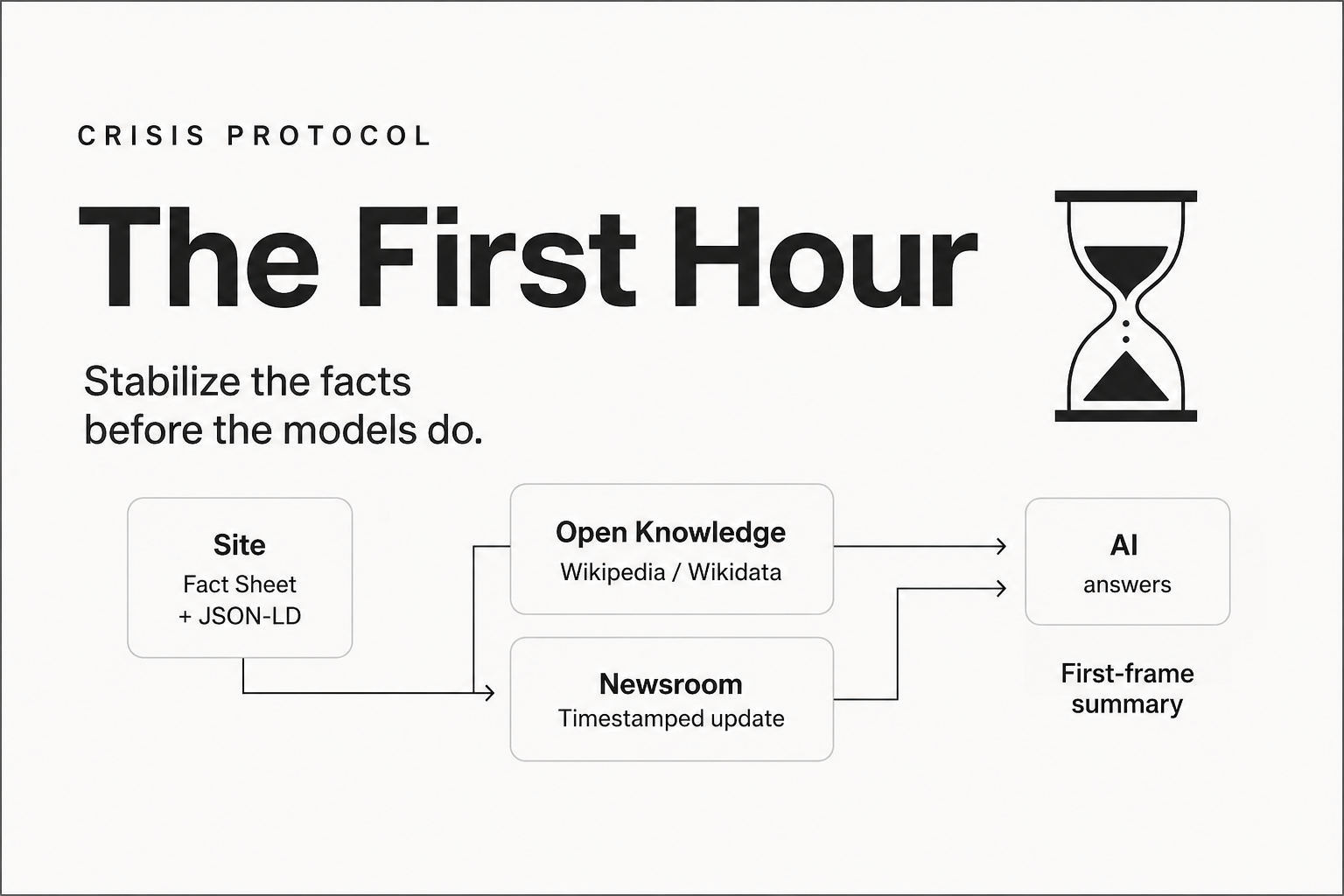
The First-Hour Machine Protocol (print and keep)
0. Pre-crisis (today, before anything happens)
- Publish an About/Fact Sheet page with canonical facts (legal name, founding year, headquarters, leadership), and mirror it as a dated, crawlable PDF. Add Organization JSON-LD (and Person markup for key leaders). Validate in Google’s Rich Results Test and the Schema Markup Validator [1][2][7].
- Ensure a clean Entity Home: one URL that ties sameAs to authoritative profiles (for example, Wikipedia/Wikidata, LinkedIn, regulated registries) [1][5].
- Establish Wikipedia governance: do not spin or sanitize; follow conflict-of-interest guidance. If you must correct facts, use the Talk page with high-quality sources; keep Wikidata in sync with verifiable statements [6][7].
1. Minute 0–15: Stabilize the facts
- Publish a holding statement on your newsroom (timestamped; plain-language summary of what is known/unknown; contact line). Crisis frameworks emphasize a first response within the first hour — ship something accurate and undateable [8][9].
- Add or refresh JSON-LD on the holding page: incident name (if applicable), spokesperson (Person), and links back to your canonical fact sheet. Validate before and after publishing [1].
2. Minute 15–30: Connect the surfaces
- Link the holding statement from the homepage and press/IR hub so crawlers find it quickly; avoid noindex or blocked resources [2].
- Issue a short press note (crawlable HTML, not image/PDF only) that repeats the same facts and URLs. If you must ship a PDF, keep the HTML summary on-page.
3. Minute 30–45: Align open knowledge
- If the crisis involves factual corrections (leadership change, facility location, dates), prepare neutral, source-backed suggestions on Wikipedia’s Talk page; avoid direct editing with a COI. Check and update Wikidata statements with citations so infoboxes can reflect the change [6][7].
- Make sure your knowledge-panel surfaces (logo, name, description on claimed panels where available) reflect the same canonical facts. Panels update from multiple sources over time; alignment accelerates convergence [3][4][5].
4. Minute 45–60: Reinforce and monitor
- Add a brief FAQ under the holding statement that answers obvious questions the press (and AIs) will ask; keep each answer source-linked.
- Monitor AI answers (for example, Gemini/Perplexity/browsing modes) to see whether your holding page and fact sheet are being cited. Expect lag; keep the owned pages fresh and consistent.
Implementation details that matter
Make the site machine-literate. On your About/Fact Sheet page, embed JSON-LD with Organization (legal name, url, logo, foundingDate, address, sameAs) and Person for your spokesperson/CEO (name, jobTitle, worksFor, image, sameAs). Do not block these pages; keep canonical tags clean; expose a square logo at a stable URL [1][2].
Treat Wikipedia ethically. Wikipedia is volunteer-run and discourages conflict-of-interest editing. Provide neutral, well-sourced suggestions on Talk pages; let independent editors act. Sync verifiable facts to Wikidata, which many infoboxes consume [6][7].
Prefer HTML over image-only PDFs. LLMs and knowledge systems ingest text better when it’s in crawlable HTML with clear headings, dates, and links. If you publish a PDF, also publish a mirrored HTML summary.
Stamp time. Visible last-updated markers on the newsroom page and fact sheet help machines prefer your version when other sources conflict.
What good looks like
- One canonical fact page on your domain; every press item links to it.
- Consistent structured data across About, Leadership, and the live statement.
- Neutral open-knowledge alignment (Talk-page requests with sources; Wikidata sync).
- Rapid iteration: updates to the holding statement as facts mature, with changed sections timestamped.
This isn’t spin. It is factual synchronization across the surfaces machines trust first.
References
[1] Google Search Central. Introduction to structured data. https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
[2] Google Search Central. General structured data guidelines. https://developers.google.com/search/docs/appearance/structured-data/sd-policies
[3] Google Support. About knowledge panels. https://support.google.com/knowledgepanel/answer/9163198
[4] Google Support. How Google’s Knowledge Graph works. https://support.google.com/knowledgepanel/answer/9787176
[5] Wikipedia contributors. Knowledge Graph (Google). Wikipedia. https://en.wikipedia.org/wiki/Knowledge_Graph_(Google)
[6] Wikipedia contributors. Conflict of interest. Wikipedia. https://en.wikipedia.org/wiki/Wikipedia:Conflict_of_interest
[7] Wikidata community. Wikidata: WikiProject Infoboxes. https://www.wikidata.org/wiki/Wikidata:WikiProject_Infoboxes
[8] Institute for Public Relations. Crisis Management and Communications. https://instituteforpr.org/crisis-management-and-communications/
[9] Public Relations Society of America (PRSA). 5 steps for navigating the first hour of a crisis. https://www.prsa.org/article/5-steps-for-navigating-the-first-hour-of-a-crisis
[10] Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., … Liu, T. (2023). A Survey on Hallucination in Large Language Models. arXiv:2311.05232. https://arxiv.org/abs/2311.05232
Related Blogs

KI hat bereits eine Meinung über Sie
Was KI im Jahr 2026 über Sie sagt – und warum Sie das nicht dem Zufall überlassen sollten.

How to Rewrite What AI Says About You (Without Touching the Code)


.png)