
KI hat bereits eine Meinung über Sie
Stellen Sie sich vor, ein institutioneller Investor prüft Ihr Unternehmen als mögliches Beteiligungsziel. Er lässt sich von ChatGPT eine Ersteinschätzung geben.
Was er bekommt, ist keine Analyse. Es ist eine Rekonstruktion – zusammengesetzt aus allem, was irgendwann irgendwo über Ihre Marke, Ihre Führung und Ihre Branche im Netz stand. Die Pressemitteilung von 2021 mit den falschen Umsatzzahlen. Das Interview, in dem Ihr CEO aus dem Zusammenhang gerissen wurde. Und vielleicht, wenn Sie Pech haben: eine Verwechslung mit einem Wettbewerber.
Die KI antwortet trotzdem. Selbstsicher, flüssig, falsch.
Was die Maschine weiß – und was sie erfindet
Große Sprachmodelle wurden auf riesigen Mengen öffentlich verfügbarer Daten trainiert: Wikipedia, Wikidata, Unternehmenswebsites, Presseberichte, LinkedIn, Crunchbase, Handelsregister. Kein Chefredakteur hat das gegengelesen. Keine Rechtsabteilung hat es freigegeben.
Das Ergebnis ist kein Unternehmensprofil. Es ist ein Mosaik – zusammengeklebt aus Quellen, die mal aktuell, mal veraltet, mal einfach falsch sind. Und weil die meisten Modelle auf Daten bis Anfang oder Mitte 2023 trainiert wurden, kann es gut sein, dass Ihre aktuelle Strategie, Ihre jüngste Transaktion oder Ihr neues Führungsteam schlicht nicht vorkommt.
Was fehlt, wird nicht offengelassen. Es wird aufgefüllt.
Der stille Maßstab: Wikipedia
Wer glaubt, Wikipedia sei ein Relikt aus der Vor-KI-Zeit, irrt. Im Gegenteil: Die Plattform ist für viele Sprachmodelle so etwas wie eine Grundwahrheit. Strukturiert, verlinkt, gut belegt – genau das, was Maschinen brauchen, um zu urteilen.
Fehlt der Wikipedia-Eintrag Ihres Unternehmens, ist er veraltet oder schlicht ungenau, pflanzt sich dieser Fehler fort. In Zusammenfassungen für Analysten. In Antworten auf Journalistenanfragen. In automatisierten Due-Diligence-Prozessen, von denen Sie nie erfahren.
Nicht weil jemand böswillig wäre. Sondern weil die Maschine nimmt, was sie findet.
Drei Ebenen, die zählen
Es gibt keine Hintertür ins Modell, keine Schnittstelle, über die Sie Ihre Daten direkt korrigieren könnten. Was es gibt, ist Einfluss auf das, was die Maschine findet – wenn Sie es strukturiert und konsistent bereitstellen.
Quellenebene. Das sind die Datenbanken, aus denen Modelle am verlässlichsten schöpfen. Wikipedia und Wikidata stehen ganz oben. Daneben: Crunchbase, Bloomberg, das Handelsregister, einschlägige Branchendatenbanken. Wer hier fehlt oder mit falschen Angaben geführt wird, hat ein Problem – auch wenn er das nie bemerkt.
Medienebene. Redaktionelle Inhalte aus anerkannten Publikationen haben für KI-Modelle besonderes Gewicht. Ein Fachbeitrag in einem Branchenmagazin, ein Interview mit der Geschäftsführung in einer überregionalen Zeitung, eine fundierte Analyse in einem Wirtschaftsmedium – das sind keine Pressearbeit im klassischen Sinne. Das sind Signale, die die Maschine ernst nimmt. Auch noch Jahre später.
Profilebene. Unternehmenswebsite, LinkedIn-Auftritt, Vorstandsprofile, Investorenseiten – weniger strukturiert als Datenbanken, aber dennoch Teil dessen, woraus Modelle ihre Urteile destillieren. Wer hier widersprüchliche oder veraltete Angaben stehen lässt, liefert der Maschine Rohmaterial für Fehler.
Was passiert, wenn Sie nichts tun
Nichts zu tun ist auch eine Entscheidung. Nur trifft sie in diesem Fall jemand anderes für Sie.
Ihre Unternehmensbewertung springt auf den Stand einer längst überholten Finanzierungsrunde zurück. Ein Nebensatz aus einem alten Interview Ihres CEOs wird zur zentralen Aussage über die Unternehmensstrategie. Ihr Kerngeschäft wird mit dem eines Wettbewerbers vermischt, weil beide im selben Atemzug erwähnt wurden. Oder Ihr Markenname taucht im Zusammenhang mit einer Kontroverse auf, die längst beigelegt ist – für die Maschine aber nie endete.
Das ist kein Worst Case. Das passiert gerade, täglich, in unzähligen Abfragen.
Kein Kommunikationsproblem. Ein Infrastrukturproblem.
Wer jetzt denkt, das sei ein Thema für die PR-Abteilung, unterschätzt die Komplexität. Eine Kommunikationsagentur kann einen Artikel platzieren. Eine SEO-Agentur kann Rankings beeinflussen. Aber das Zusammenspiel zwischen Datenbankeinträgen, redaktionellem Gewicht, Profilstruktur und algorithmischer Sichtbarkeit – das ist eine eigene Disziplin.
Eine, die es vor drei Jahren noch nicht gab.
Die Frage ist nicht mehr, ob KI über Ihr Unternehmen urteilt. Sie tut es bereits. Die Frage ist nur, ob das, was sie sagt, der Wahrheit entspricht.
Und wer das sicherstellen möchte, sollte besser nicht warten, bis ein Analyst, ein Journalist oder ein Geschäftspartner ihn darauf anspricht.
Referenzen
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., et al. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165. https://arxiv.org/abs/2005.14165
- Wikipedia contributors. (2024). Model collapse. Wikipedia. https://en.wikipedia.org/wiki/Model_collapse
- Shumailov, I., Crowley, E. J., Clegg, T., Mullins, N., Rolland, P., Cai, C., et al. (2023). The Curse of Recursion: Training on Generated Data Makes Models Forget. arXiv:2305.17493. https://arxiv.org/abs/2305.17493
- OpenAI. (2023). GPT-4 Technical Report. https://cdn.openai.com/papers/gpt-4.pdf
- Verifiable Mind. (2025). What AI Forgot: The Silent Power of Wikipedia. Medium. https://medium.com/@verifiablemind/what-ai-forgot-the-silent-power-of-wikipedia-06dd89d60518


KI hat bereits eine Meinung über Sie
The AI Mirror Is Already On
Ask any modern AI tool a question about a person, company, or topic, and it won’t hesitate to answer — confidently, fluently, and fast. What few realize: those answers are not pulled from a central database or verified source. They’re constructed from a fragmented, historical trail of what’s been written about you online.
That trail may be outdated. It may be incorrect. Or it may not even exist.
But increasingly, this is the version of you that investors, journalists, employers, and clients meet first — not through your website or your résumé, but through a machine-generated summary.
AI Is Already Summarizing You
Tools like ChatGPT, Claude, Perplexity, Gemini, and Meta AI are now the default gateways to information. When someone types “Who is [Your Name]?” or “What does [Company] do?”, they’re not getting raw data. They’re getting a distillation — a compressed, confident narrative based on whatever the model has seen and remembered.
Language models like GPT-4 were trained on vast portions of the internet, including Wikipedia, Wikidata, public company websites, media articles, LinkedIn, Crunchbase, court records, and more. Not all of these sources are accurate. Not all are current. And none are cited by default.
In most cases, you won’t even know you’re being quoted.
You Are Now a Prompt Response
It’s no longer just about what Google says about you. It’s about what AI systems assume.
For public figures, CEOs, founders, scientists, and even private individuals with a digital footprint, that means your professional identity has effectively become a machine-readable résumé — whether or not you ever chose to write one.
This includes:
- Roles and titles (often based on outdated bios)
- Quotes, interviews, or controversies
- Company affiliations and valuations
- Research or academic contributions
- Public statements or positions
- Media coverage — positive or negative
These facts (or partial facts) are then reproduced — sometimes slightly altered — across countless AI outputs.
What’s in the Machine’s Memory?
Many large language models (LLMs) were trained on data up to early or mid-2023. If your public bio was vague or missing at the time, the model’s knowledge about you may be nonexistent or heavily inferred.
In our previous article — What AI Forgot: The Silent Power of Wikipedia — we examined how foundational sources like Wikipedia have become core to machine knowledge. Because of their structure, citations, and reliability, they are not just consulted by AI. They shape how it thinks.
Wikipedia, in particular, functions as a kind of “ground truth” for many models. If your presence there is absent or inaccurate, it may create a cascading effect: LinkedIn summaries get misaligned, PR references go unnoticed, and your digital identity becomes distorted at scale.
Even newer AI models that access the live web rely on cached, ranked, or reinterpreted content. What’s surfaced is not what’s real — it’s what’s available.
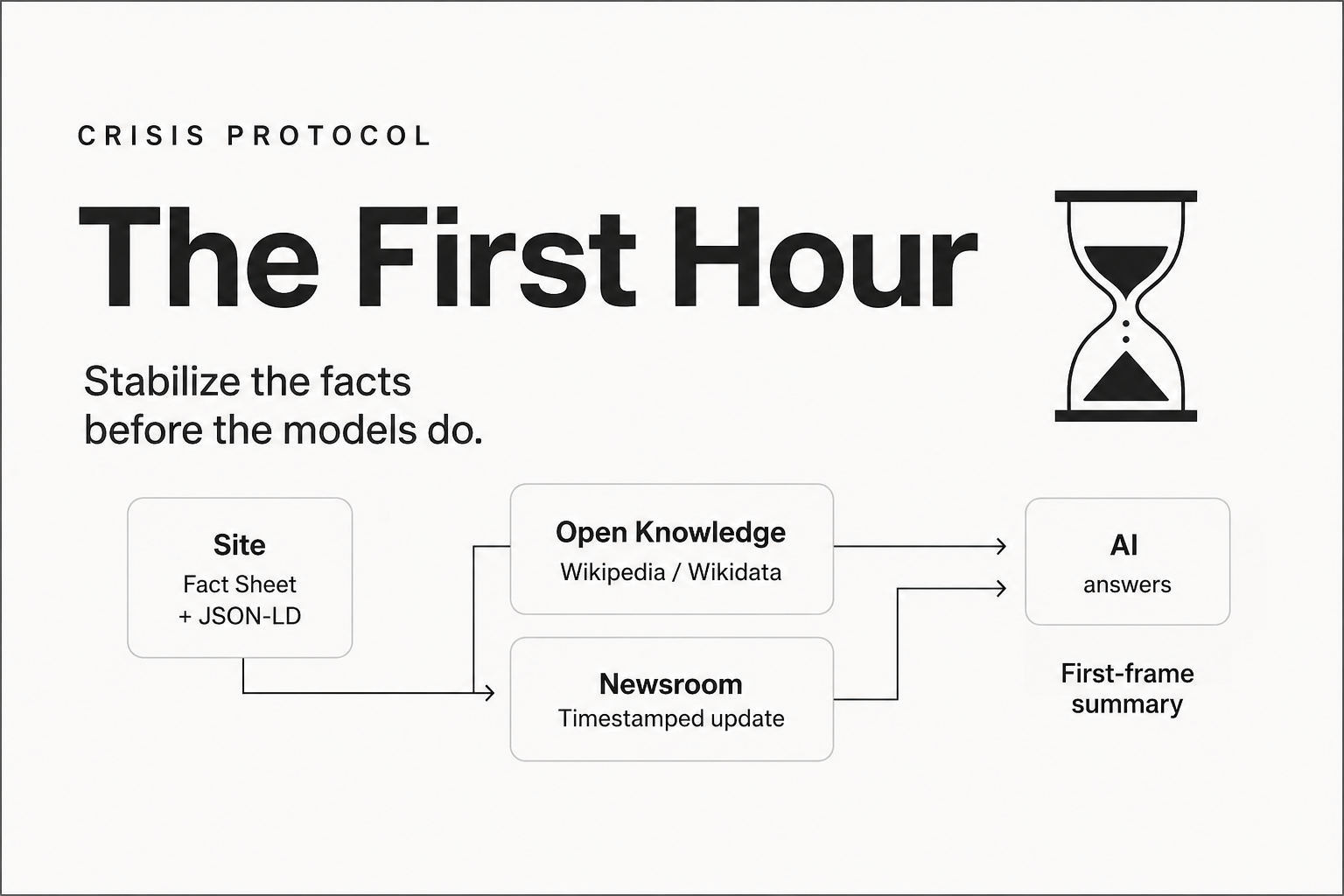
How to Shape It: A Three-Layer Checklist
The good news: your AI-facing profile can be shaped — without manipulating anything or touching code. You simply need to strengthen what’s called your structured public presence.
Here’s a practical checklist:
1. Source Layer
These are structured, machine-readable databases that feed directly into AI systems.
- Wikipedia: If eligible, ensure you have a neutral, cited, and regularly updated article.
- Wikidata: Linked to Wikipedia, this structured database provides facts that models use for summarization.
- Crunchbase, Bloomberg, GND, ORCID, IMDB (as relevant): Correct titles, affiliations, and dates.
- Company registry entries: These are increasingly crawled and included.
Tip: Many of these profiles are editable or can be requested for correction via official channels.
2. Media Layer
Models give extra weight to high-authority, editorial content.
- Published interviews, podcast features, profiles in reputable publications
- Authored articles with bylines
- Mentions in industry roundups or academic citations
Tip: Articles published under your name on platforms like Medium, Substack, or academic journals are frequently referenced — even years later.
3. Social Layer
While often less structured, social profiles are still referenced in models trained on web crawls.
- LinkedIn: Your headline and “About” section are often used verbatim.
- Personal bios on websites, speaking engagements, or press releases
- Verified profiles on platforms with high trust scores
Tip: The more consistent and structured these are, the more clearly AI models can interpret them.
What If You Do Nothing?
If you don’t shape this information proactively, the machines will fill in the gaps — often incorrectly.
- You may be misattributed to another person with a similar name.
- Your company’s revenue or headcount may be hallucinated from a press release.
- Your job title may revert to what it was in 2019.
- A one-off media quote might become your defining narrative.
This isn’t about vanity. It’s about professional control. And in many sectors — from politics to science to venture capital — the cost of inaccuracy is reputational, operational, and sometimes even legal.
Your AI Résumé Is Already Being Written
Whether or not you prompt it, AI is already answering questions about you. The only choice you have is whether those answers are correct.
But shaping that narrative has become more complex. The once-straightforward work of correcting a bio or publishing an article is now entangled in a multi-layered ecosystem — where source accuracy, content structure, domain trust, and algorithmic visibility all intersect.
To get it right, you no longer just need a writer, an SEO, or a PR agent.
You need a conductor.
Someone who understands how the layers interact — from Wikipedia and Wikidata to media placements and LinkedIn summaries — and how those signals converge into the final AI answer.
Because if you don’t coordinate your digital footprint, someone else — or something else — will.
And the next time someone asks ChatGPT about you, the machine will answer… with or without your input.
References
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., et al. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165. https://arxiv.org/abs/2005.14165
- Wikipedia contributors. (2024). Model collapse. Wikipedia. https://en.wikipedia.org/wiki/Model_collapse
- Shumailov, I., Crowley, E. J., Clegg, T., Mullins, N., Rolland, P., Cai, C., et al. (2023). The Curse of Recursion: Training on Generated Data Makes Models Forget. arXiv:2305.17493. https://arxiv.org/abs/2305.17493
- OpenAI. (2023). GPT-4 Technical Report. https://cdn.openai.com/papers/gpt-4.pdf
- Verifiable Mind. (2025). What AI Forgot: The Silent Power of Wikipedia. Medium. https://medium.com/@verifiablemind/what-ai-forgot-the-silent-power-of-wikipedia-06dd89d60518
Related Blogs

How to Rewrite What AI Says About You (Without Touching the Code)
Reputation is now infrastructure
Jahrzehntelang wurde Reputation als Kommunikationsproblem behandelt.


.png)